RAG چیست و چرا اهمیت دارد؟
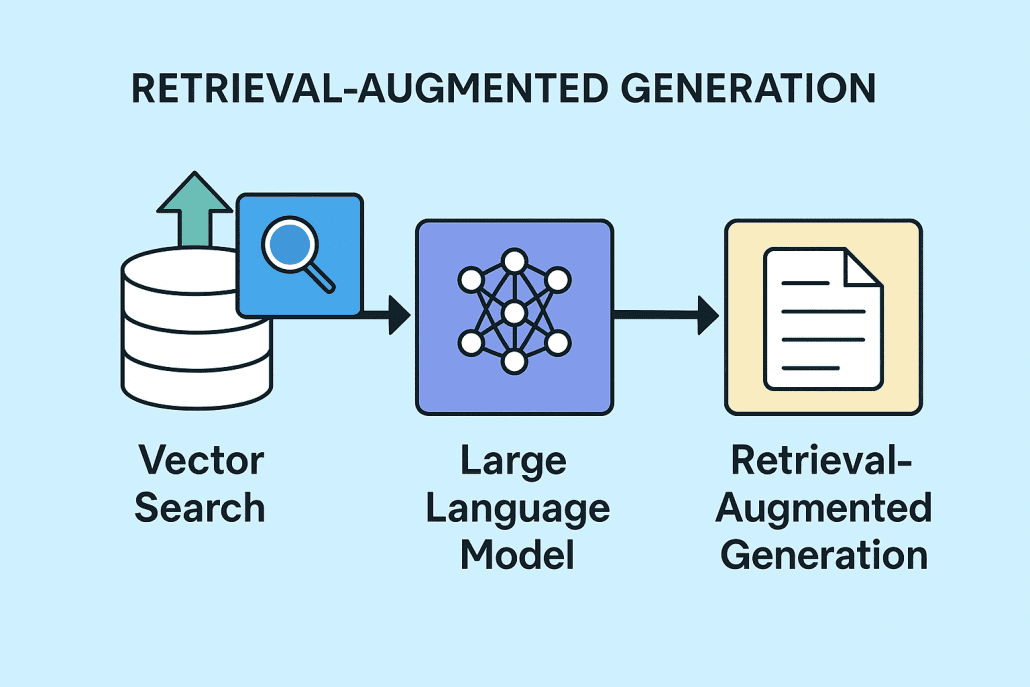
تصور کنید یک سامانهی هوشمند که نه تنها پاسخگوی سؤالات شماست، بلکه با جستجو در منابع معتبر، اطلاعات بهروز، دقیق و مبتنی بر واقعیت را استخراج کرده و در قالبی روان و تخصصی ارائه میدهد. این دقیقاً همان قابلیتی است که معماری پیشرفتهی RAG (Retrieval-Augmented Generation) به دستیارهای مجازی و چتباتهای سازمانی میبخشد.
فناوری RAG با ترکیب قدرت جستجوی برداری و مدلهای زبانی بزرگ (LLMs)، امکان پاسخدهی به سوالات پیچیده و تخصصی را با دقت بالا فراهم میسازد. اگر به دنبال ساخت یک سیستم هوش مصنوعی پاسخگو با پشتوانه واقعی از دانش هستید، RAG انتخابی کلیدی است.
برای بهرهبرداری از پتانسیل کامل این معماری، زیرساخت سختافزاری قدرتمند امری ضروری است. سرورهای پیشرفته Supermicro با پشتیبانی از پردازندههای گرافیکی و حافظههای پرظرفیت، گزینهای ایدهآل برای اجرای روان و سریع مدلهای LLM و RAG هستند.
جهت مشاوره، خرید یا راهاندازی سرور Supermicro مناسب برای پروژههای مبتنی بر RAG، با تیم فنی ما در تماس باشید.
RAG چیست و چرا اهمیت دارد؟
Retrieval‑Augmented Generation (RAG) یک معماری ترکیبی است که با تلفیق جستجوی مستندات (Retrieval) و تولید متن (Generation) در مدلهای زبان بزرگ (LLM)، پاسخهایی دقیقتر و کاربردیتر تولید میکند. برخلاف رویکردهای صرفاً تولیدی که ممکن است اطلاعات نادرست («hallucination») ارائه دهند، RAG ابتدا دانش مرتبط را از یک پایگاه دانش واکشی میکند و سپس با کمک LLM، متن نهایی را بر پایهٔ آن دادهها میسازد.
از مازیای RAG می توان به موارد زیر اشاره کرد:
- کاهش خطا: با ارجاع مستقیم به منابع واقعی
- بهروزرسانی آسان دانش: بدون نیاز به آموزش مجدد کامل مدل
- انعطافپذیری بالا: قابل ادغام با انواع پایگاههای داده و vector store
مراحل اصلی در پیادهسازی RAG
آمادهسازی و نمایهسازی دانش
- جمعآوری اسناد: PDF، متنهای ویکیپدیا، پایگاه دادههای سازمانی
- استخراج embedding: با مدلهای Sentence‑Transformer یا OpenAI Embeddings
- ساخت نمایه برداری: ذخیره embeddings در یک vector store
لایهٔ بازیابی (Retrieval)
- پرسوجوی برداری: یافتن k سند نزدیک به embeddingِ سؤال
- پرسوجوی متنی (optional): فیلترهای پایهای با ElasticSearch یا OpenSearch
لایهٔ تولید (Generation)
- ورود دادههای بازیابیشده به LLM: مانند GPT-4 یا LLaMA
- تنظیم پارامترها: مقدار
k,temperature,max_tokens
استقرار و مانیتورینگ
- Inference Server: Triton Inference Server یا Ray Serve
- MLOps: ابزارهایی مثل Kubeflow یا MLflow برای CI/CD، و Prometheus/Grafana برای نظارت
کاربردهای سازمانی RAG
- چتباتهای آموزشی و پشتیبانی: پاسخهای دقیق به پرسشهای تخصصی
- خلاصهسازی مستندات: تولید خلاصههای خودکار از گزارشها و مقالات
- جستجوی هوشمند در اسناد: ترکیب جستجوی برداری با LLM برای نتایج عمیقتر
- تحلیل پایگاههای دانش: استخراج مفهوم و روابط بین دادهها
بهترین ابزارهای متنباز برای راهاندازی RAG
| نام ابزار | لینک GitHub | توضیح کوتاه |
|---|---|---|
| Haystack | https://github.com/deepset-ai/haystack | چارچوب Python برای ساخت pipelineهای RAG با پشتیبانی از Elasticsearch، FAISS، Milvus و Weaviate. |
| LangChain | https://github.com/langchain-ai/langchain | فریمورک قابل توسعه برای زنجیرهسازی LLM و ابزارهای retrieval و generation. |
| LlamaIndex | https://github.com/jerryjliu/llama_index | (قبلاً GPT Index) ابزار مدیریت اسناد و pipelineهای ساده RAG. |
| FAISS | https://github.com/facebookresearch/faiss | کتابخانهٔ قدرتمند نمایهسازی برداری از فیسبوک برای جستجوی nearest neighbor. |
| Milvus | https://github.com/milvus-io/milvus | سیستم vector database توزیعشده با مقیاسپذیری بالا. |
| Weaviate | https://github.com/semi-technologies/weaviate | پایگاه داده برداری خودروند با قابلیتهای GraphQL و پلاگینهای NLP. |
| Qdrant | https://github.com/qdrant/qdrant | موتور جستجوی برداری با REST API سبک و عملکرد بالا. |
نکته: برای هر پروژه، بر اساس حجم داده و نیازهای latency و throughput، یک یا چند vector store را انتخاب و با pipeline LLM ادغام کنید.
نکات کلیدی برای بهینهسازی SEO
- کلمات کلیدی اصلی:
- RAG، Retrieval‑Augmented Generation، vector search، LLM integration
- کلمات کلیدی بلند (Long‑Tail):
- «نحوه راهاندازی RAG با Haystack»، «معماری RAG با FAISS و GPT-4»
- Schema Markup:
HowToبرای گامهای پیادهسازیSoftwareApplicationوDatasetبرای ابزارها و پایگاههای داده
- تگهای عنوان و Alt Text:
- H2: «مراحل پیادهسازی RAG در پروژههای NLP»
- تصاویر:
alt="معماری لایههای RAG با Haystack"
- لینکسازی داخلی و خارجی:
- لینک به مقالات مقدماتی AI و LLM در بلاگ خود
- لینک به GitHub ابزارها و مستندات رسمی آنها
- سرعت بارگذاری:
- استفاده از lazy‑load برای تصاویر
- فشردهسازی فایلهای CSS/JS
با رعایت ساختار بالا و بهرهگیری از ابزارهای متنباز معرفیشده، میتوانید یک زیرساخت RAG قوی و مقیاسپذیر بسازید که پاسخهای دقیق و متکی بر دانش واقعی را با latency پایین در اختیار کاربران و سیستمهای خود قرار دهد.
زیرساخت سرور RAG – چه سروی نیاز دارید؟
معماری RAG به دلیل پردازش همزمان چند مرحلهای (بازیابی + تولید)، نیازمند زیرساختی با عملکرد بالا است. برای اینکه سیستم RAG شما در مقیاس سازمانی و با کمترین تأخیر (low latency) کار کند، انتخاب درست سرور، حافظه، GPU و منابع ذخیرهسازی حیاتی است.
مشخصات فنی پیشنهادی برای اجرای RAG:
| بخش | مشخصات پیشنهادی | توضیحات |
|---|---|---|
| پردازنده (CPU) | 2× Intel Xeon Gold | پردازش همزمان چند Thread برای مدیریت I/O بازیابی |
| رم (RAM) | حداقل 256GB DDR4/5 | بارگذاری اسناد، نگهداری embedding cache، بهینه برای inference چندگانه |
| GPU | 2× NVIDIA A100 / H100 / L40S / H200 | ضروری برای اجرای مدلهای LLM با سرعت بالا و پشتیبانی از FP16 |
| ذخیرهسازی | NVMe SSD – حداقل 4TB | برای بارگذاری سریع embeddingها و اسناد بازیابیشده |
| شبکه | 25/50Gbps Ethernet | در صورت استفاده از سرویسهای بازیابی توزیعشده (distributed retrieval) |
| سیستم عامل | Ubuntu 22.04 LTS یا RHEL 9 | با درایورهای CUDA، PyTorch و Docker آماده اجرا |
چرا سرور Supermicro برای RAG مناسب است؟
سرورهای Supermicro با طراحی ماژولار، چگالی بالا و پشتیبانی از جدیدترین GPUهای NVIDIA، انتخابی ایدهآل برای پروژههای مبتنی بر Retrieval-Augmented Generation (RAG) هستند. این سرورها با تمرکز بر عملکرد، بازدهی مصرف انرژی و قابلیت اطمینان در سطح دیتاسنتر طراحی شدهاند و گزینهای محبوب در بین مراکز داده، استارتاپهای هوش مصنوعی و تیمهای تحقیقاتی محسوب میشوند.
مزایای کلیدی سرورهای Supermicro برای اجرای RAG:
پشتیبانی از چند GPU پرقدرت
مدلهایی مانند سرور هوش مصنوعی Supermicro SYS-741GE تا 4 عدد GPU و مدل هایی مانند سرور هوش مصنوعی Supermicro SYS-421GE تا 8 عدد GPU از نوع NVIDIA A100/H100 را پشتیبانی میکنند – مناسب برای inference مدلهای LLM با حجم بالا.طراحی خنکسازی بهینه برای بارهای AI
جریان هوای تخصصی در chassis باعث عملکرد پایدار GPU حتی در استفادههای طولانی میشود.پشتیبانی کامل از PCIe Gen4 و NVMe
برای انتقال سریع دادهها بین حافظه، GPU و فضای ذخیرهسازی برداری (vector DBs).قابلیت مقیاسپذیری بالا و مدیریت از راه دور
ابزارهای IPMI و Redfish API امکان مانیتورینگ و مدیریت ساده در محیطهای MLOps را فراهم میکنند.
با انتخاب سرورهای Supermicro، نه تنها از قدرت سختافزاری بالا بهرهمند میشوید، بلکه از انعطافپذیری و عملکرد پایدار در اجرای pipelineهای پیچیده RAG نیز برخوردار خواهید بود.








دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.