کدام GPU ها برای یادگیری عمیق Deep Learning مناسب هستند؟

تجربیات و پیشنهادات سورین برای استفاده از GPU ها در یادگیری عمیق
یادگیری عمیق یک زمینه کاربردی با نیاز توان محاسباتی بالا است و انتخاب GPU برای کامپیوتر یادگیری عمیق شما تاثیر بسزایی روی عملیات یادگیری عمیق کاربران خواهد داشت. بدون استفاده از پردازنده گرافیکی، ممکن است اتمام یک آزمایش ماهها به طول بینجامد، یا برای مشاهده اثر تغییر یک پارامتر یک روز یا بیشتر زمان لازم باشد تا متوجه شوید مدل واگرا شده است.
با استفاده از یک GPU مناسب برای سرور یادگیری عمیق شما، میتوان به سرعت از طرح ها و پارامترهای شبکه های عمیق را تغییر داد و زمان انجام آزمایشها را از چندین ماه به چند ساعت، از چند روز به چند ساعت و از چندین ساعت به چند دقیقه کاهش داد. بنابراین انتخاب درست GPU هنگام خرید بسیار مهم است. حال این سوال مطرح است که چگونه GPU را انتخاب کنید که برای کاربرد شما مناسب است؟ این پست وبلاگ سورین به این پرسش پاسخ خواهد داد و به شما مشاوره ارائه میدهد و به شما کمک می کند تا اپردازنده گرافیکی را انتخاب کنید که برای شما مناسب است.
زمانی که شما در حال فراگیری یادگیری عمیق هستید، داشتن یک GPU سریع اهمیت بالایی دارد، زیرا این امر باعث می شود تا تجربه شما به سرعت عملی شود و شما بتوانید از تخصص خود در حل مشکلات جدید بهره ببرید. بدون این بازخورد سریع، زمان زیادی برای یادگیری از اشتباهات صرف می شود و این می تواند استفاده از یادگیری عمیق را خسته کننده و نا امید کننده جلوه دهد.
آیا استفاده از چندین GPU مناسب است؟
با توجه به تاثیر چشمگیر استفاده از GPU در یادگیری عمیق، سورین در یک پروژه مشترک تحقیقاتی یک کلاستر GPU با شبکه InfiniBand 40 گیگابیت بر ثانیه طراحی و پیادهسازی کرده است. هدف این پروژه بررسی این موضوع بود که آیا میتوان با استفاده از چندین GPU به نتایج بهتری در یادگیری عمیق دست یافت؟
ما به سرعت متوجه شدیم که نه تنها موازی سازی شبکههای عصبی روی چند GPU پیچیده نیست، بلکه افزایش سرعت برای شبکههای عصبی سنگین، چندان راضی کننده نبود. شبکه های عصبی کوچک میتوانند با استفاده از موازی سازی داده، به شکل کارایی موازی شوند، اما شبکههای عصبی بزرگتر تقریبا افزایش سرعت خاصی نخواهند داشت.
پیشنهاد سورین برای
تجزیه و تحلیل دقیق تاثیر موازی سازی در یادگیری عمیق، بر اساس یک تکنیک افزایش سرعت در کلاسترهای GPU از 23 برابر به 50 برابر، برای یک سیستم با 96 GPU در ICLR 2016 منتشر شده است. در این تجزیه و تحلیل مشخص شده است که موازی سازی شبکههای convolution و recurrent به مراتب ساده تر است، به خصوص اگر فقط از یک کامپیوتر یا 4 پردازنده گرافیکی استفاده شود. بنابراین با وجود اینکه ابزارهای مدرن برای موازی سازی بهینه نیستند، هنوز می توان به افزایش سرعت خوبی دست یافت.
تجربه کاربران در استفاده از تکنیک های موازی سازی در قالب Framework های محبوب در مقایسه با سه سال پیش بسیار بهبود یافته است. الگوریتمهای این چارچوبها نسبتا ساده هستند و قادر به استفاده از کلاسترهای GPU نیستند، اما در صورت استفاده تا 4 GPU کارایی خوبی را ارائه می دهند. برای کانولوشن، با استفاده از 2، 3 یا 4 GPU به ترتیب انتظار افزایش سرعت تا 1.9 برابر، 2.8 برابر یا 3.5 برابر را داشته باشید؛ برای شبکههای recurrent، طول دنباله مهمترین پارامتر است و برای مسائل رایج NLP می توان سرعت های مشابه یا کمی بدتر از شبکههای کانولوشن را انتظار داشت. به طور معمول، شبکههای کاملا متصل، عملکرد ضعیفی برای موازی سازی دادهها دارند و الگوریتم های پیشرفته تری برای سرعت بخشیدن به این بخش های شبکه لازم است.
بنابراین امروزه افزایش سرعت با استفاده از چندین پردازنده گرافیکی میتواند فرایند یادگیری ماشین را بسیار راحت تر نماید و اگر بودجه کافی وجود داشته باشد، استفاده از چندین پردازنده گرافیکی میتواند بسیار مفید باشد.
استفاده از چند GPU بدون موازیسازی
یکی دیگر از مزیتهای استفاده از چندین پردازنده گرافیکی، این است که حتی اگر شما الگوریتمهای موازی نداشته باشید، می توانید چندین الگوریتم یا آزمایش را به طور جداگانه در هر GPU اجرا کنید. سرعت اجرای شما افزایش نمییاید، اما با استفاده از الگوریتمهای یا پارامترهای مختلف در یک زمان کارایی بیشتری کسب میکنید. در صورتی که هدف اصلی شما این است که در اسرع وقت عملیات یادگیری عمیق را به انجام برسانید، این بسیار مفید است. همچنین برای محققانی که می خواهند چندین نسخه از یک الگوریتم جدید را در یک زمان امتحان کنند بسیار مفید است.
این به لحاظ روانشناختی مهم است اگر بخواهید یادگیری عمیق را بیاموزید. با فواصل کوتاهتر برای انجام یک کار و دریافت بازخورد برای آن کار، مغز در ادغام قطعات حافظه مربوط به آن کار و تشکیل یک تصویر منسجم عملکرد بهتری خواهد داشت. اگر شما دو شبکه کانولوشن را در دو GPU مجزا در مجموعه دادههای کوچک آموزش دهید، با سرعت بیشتری متوجه خواهید شد که برای انجام بهتر کار، کدام فرایند مناسب است؛ شما به راحتی قادر به شناسایی الگوهای خطای اعتبارسنج متقابلی و تفسیر آنها به درستی خواهید بود. شما قادر به شناسایی الگوهایی هستید که برای شما مشخص میکند که کدام پارامتر یا لایه باید اضافه شود، حذف شود یا تنظیم شود.
ما معتقدیم استفاده از چندین پردازنده گرافیکی به جای تنها یک GPU برای این کاربرد مفیدتر است، زیرا میتوان به سرعت به یک پیکربندی مناسب رسید. پس از آنکه طیف مناسب از پارامترها یا معماری ها مشخص گردید، می توان از موازی سازی چندین GPU برای آموزش شبکه نهایی استفاده کرد.
بنابراین، به طور کلی می توان گفت که یک GPU تقریبا برای انجام هر کاری کافی به نظر میرسد، اما استفاده از چند GPU برای تسریع مدل های یادگیری عمیق اهمیت بالایی دارد. استفاده از GPUهای چندگانه ارزان قیمت نیز برای سرعت بخشیدن به فرایند یادگیری عمیق توصیه میگردد. این GPUها برای اهداف تحقیقاتی بسیار مناسب هستند.
انودیا یا AMD
کتابخانههای استاندارد NVIDIA ساخت اولین کتابخانههای یادگیری عمیق را به زبان CUDA میسر ساختند، در حالی که چنین کتابخانههای استاندارد قدرتمندی برای OpenCL AMD وجود نداشت. این مزیت اولیه همراه با پشتیبانی همهجانبه از NVIDIA به سرعت میزان استفاده از CUDA را افزایش داد. این بدان معنی است که اگر شما از GPUهای NVIDIA استفاده کنید، اگر به مورد اشتباهی برخورد کنید، به راحتی راه حلی پیدا خواهید کرد، در صورتی که خودتان برنامهنویسی CUDA را انجام می دهید، پشتیبانی و مشاوره خواهید داشت و متوجه خواهید شد که اکثر کتابخانه های عمیق یادگیری بهترین پشتیبانی را از GPUهای NVIDIA دارند. این یک نقطه قوت عالی برای GPUهای NVIDIA است.
از سوی دیگر، NVIDIA در حال حاضر سیاستی دارد که در آن استفاده از CUDA در مراکز داده فقط برای GPUهای Tesla مجاز است و برای کارتهای GTX یا RTX مجاز نیست. مشخص نیست که منظور از «مراکز داده» چیست، اما این بدان معنی است که سازمانها و دانشگاهها به دلیل ترس از مسائل قانونی، اغلب مجبور به خرید GPUهای گران قیمت و پرهزینه Tesla باشند. با این حال، کارتهای Tesla هیچ مزیت واقعی نسبت به کارتهای GTX و RTX ندارد و تا 10 برابر گرانتر هستند.
NVIDIA توانسته این کار را بدون هیچ گونه مانعی پیش ببرد که نشانه قدرت انحصاری آنهاست. آنها میتوانند هرکاری را که می خواهند انجام دهند و ما باید این شرایط را قبول کنیم. اگر شما مزایای عمدهای را که کارتهای گرافیک NVIDIA از نظر پشتیبانی دارند را انتخاب کنید، همچنین باید قبول کنید که ممکن است از طرف آنها تحت فشار قرار بگیرید.
HIP از طریق ROCm قادر است GPUهای NVIDIA و AMD را تحت یک زبان برنامه نویسی مشترک مدیریت کند که دستورات این زبان قبل از اینکه به GPU متصل شود، به زبان GPU کامپایل میشود. اگر ما تمام کد GPU خود را در HIP داشته باشیم، این یک نقطه عطف مهم است. اما داستان پیچیدهتر از این خواهد بود زیرا استفاده از کدهای مبتنی بر کتابخانههای TensorFlow و PyTorch بسیار سخت است. TensorFlow تا حدودی از GPUهای AMD پشتیبانی میکند و تمام شبکههای اصلی را می توان در GPUهای AMD اجرا کرد، اما اگر میخواهید شبکههای جدیدی را توسعه دهید، ممکن است برخی جزئیات از دست برود که در نتیجه میتواند شما را از اجرای آنچه در نظر دارید باز دارد. جامعه ROCm خیلی بزرگ نیست و بنابراین قادر نیست که مشکلات را به سرعت حل کند. به نظر می رسد که باید از طرف AMD هزینه بیشتری برای توسعه و حمایت از یادگیری عمیق صورت بگیرد که در حال حاضر به کندی پیش میرود.
با این حال، GPUهای AMD در مقایسه با GPUهای NVIDIA از کارایی بیشتری برخوردارند و نسل بعدی GPUهای AMD با عنوان Vega 20 یک پردازنده محاسباتی است که از هستههای Tensor مانند واحدهای محاسباتی بهره خواهد برد.
با تمام این اوصاف نمیتوان استفاده از GPUهای AMD را به کاربران معمولی توصیه کرد که تنها میخواهند به سادگی از پردازندههای گرافیکی خود استفاده کنند. کاربران با تجربهتر باید مشکلات کمتری داشته باشند و با حمایت از GPUهای AMD و توسعهدهندگان ROCm / HIP به مبارزه با موقعیت انحصاری NVIDIA کمک کنند، این امر در بلند مدت به نفع همه است. اگر شما یک برنامه نویس GPU هستید و میخواهید سهم مهمی در محاسبات مبتنی بر GPU داشته باشید، یک GPU AMD ممکن است بهترین راه برای تاثیر گذاری خوب در طولانی مدت باشد. برای دیگران، GPU های NVIDIA ممکن است انتخاب بهتر باشد.
تجربه سورین در استفاده از پردازندههای کمکی اینتل با عنوان Xeon Phi چندان امیدوار کننده نیست و نمیتوان آنها را به عنوان یک رقیب جدی برای کارتهای NVIDIA یا AMD لحاظ کرد. اگر شما قصد استفاده از Xeon Phi را دارید، باید توجه داشته باشید که ممکن است با کمبود پشتیبانی مواجه شوید. مشکلات محاسباتی که ممکن است سبب گردد بخشی از کد کندتر از CPU اجرا شود، نوشتن کد بهینه سیار دشوار است، پشتیبانی کامل از ویژگیهای C++ 11 وجود ندارد، برخی از الگوهای طراحی مهم GPU توسط کامپایلر پشتیبانی نمیشود، سازگاری کمی با دیگر کتابخانه ها که بر پایه BLAS استوار هستند (NumPy و SciPy)، وجود دارد و بسیاری از مشکلات دیگر.
چه عاملی سبب میشود یک GPU سریعتر از دیگری باشد؟
اولین سوال این است که مهمترین ویژگی GPU برای عملکرد سریع در یادگیری عمیق کدام است؟: تعداد هسته CUDA؟ سرعت ساعت؟ میزان RAM؟
در حالی که در گذشته “پهنای باند حافظه” مقیاس خوبی برای عملکرد GPU بود، امروزه از اهمیت چندانی برخوردار نیست. به این دلیل که سختافزار و نرمافزار GPU در طول سالیان به گونهای توسعه یافته است که پهنای باند معیار خوبی برای کارایی GPU به حساب نمیآید. معرفی هستههای تنسور در GPUهای معمولی، موضوع را پیچیدهتر میکند. در حال حاضر ترکیبی از پهنای باند، FLOPS و هستههای تنسور بهترین شاخص برای عملکرد یک GPU است.
یکی از مواردی که میتواند در انتخاب آگاهانه GPU به شما کمک کند، این است که بدانید چه بخشی از سختافزار GPU برای سرعت بخشیدن به دو فعالیت مهم در عملیات تنسور، ضرب ماتریس و کانولوشن، اهمیت دارند.
یک عامل ساده و موثر برای ضرب ماتریس محدودیت پهنای باند است. اگر شما از LSTMها و دیگر شبکههای recurrent استفاده میکنید که مقدار زیادی عملیات ضرب ماتریس انجام میدهند، پهنای باند حافظه مهمترین ویژگی GPU است که باید در آن دقت کنید.
به همین صورت، شبکههای کانولوشن با سرعت محاسبه محدود می شود. بنابراین TFLOP هر GPU بهترین شاخص برای عملکرد ResNets و دیگر معماریهای کانولوشن است.
هستههای تنسور معادله را کمی تغییر میدهند. این هستهها واحدهای محاسباتی ویژهای هستند که میتوانند سرعت محاسبات را افزایش دهند، اما در مورد پهنای باند حافظه تاثیری ندارند. در نتیجه بیشترین سود را برای شبکههای کانولوشن دارند که با استفاده از هستههای تنسور، حدود 30 تا 100٪ سریعتر اجرا میشوند.
علاوه بر اینکه هستههای تنسور سرعت انجام محاسبات را افزایش میدهند، محاسبات را با استفاده از اعداد 16 بیتی انجام میدهند. این نیز یک مزیت بزرگ برای ضرب ماتریس است؛ زیرا با استفاده از اعداد 16 بیتی به جای 32 بیتی، میتوان با استفاده از پهنای باند حافظه یکسان، تعداد انتقال اعداد را در یک ماتریس دو برابر کرد. به طور کلی در صورت تغییر اعداد از 32 بیت به 16 بیت میتوان انتظار افزایش سرعت 100 تا 300 درصدی را داشت. علاوه بر آن در استفاده LSTها از هستههای تنسور میتوان انتظار افزایش سرعت 20 تا 60 درصدی را داشت.
بنابراین، به طور کلی، بهترین قاعده کلی این است که: اگر از RNN استفاده می کنید، به پهنای باند دقت کنید؛ اگر از کانولوشن استفاده می کنید، به FLOPS توجه کنید؛ اگر می توانید از هستههای تنسور استفاده کنید.
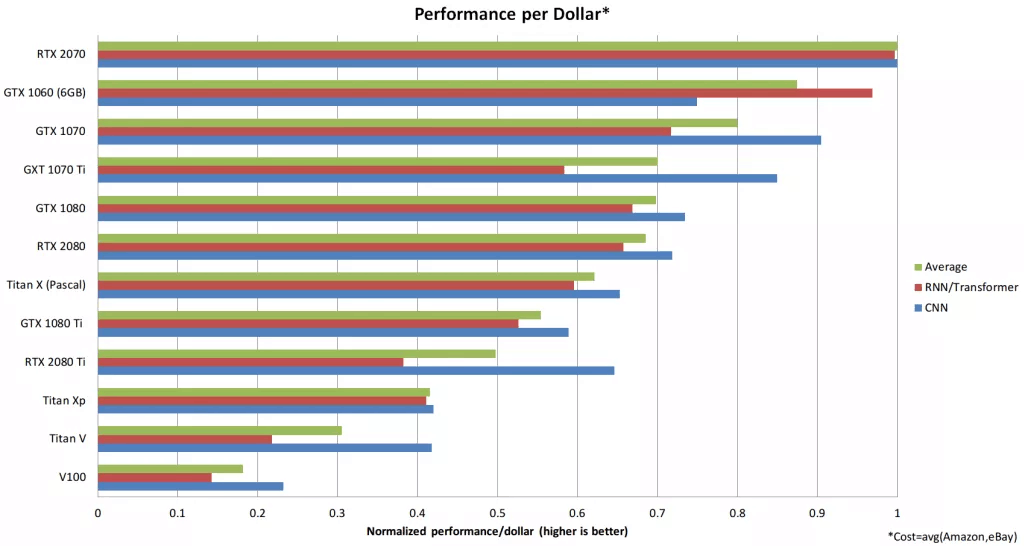
مقایسه عملکرد پردازنده های گرافیکی و TPU. سرعت RTX 2080Ti حدود دو برابر سرعت GTX 1080 Ti است: 0.77 در مقابل 0.4
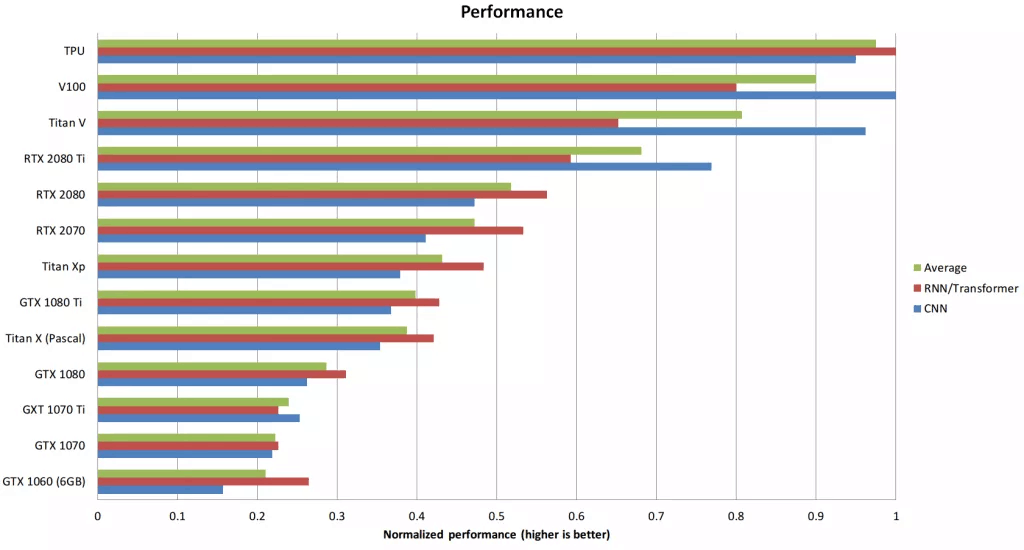
احتمالا نسبت هزینه به کارایی GPU مهمترین معیار انتخاب یک پردازنده گرافیکی است. نمودار زیر تجزیه و تحلیل نسبت هزینه به کارایی را نشان میدهد که دربرگیرنده مواردی نظیر پهنای باند حافظه، TFLOPs و هستههای تنسور است.